Procedimientos almacenados – SQL Server
2005
Autora:
Maika Hernández
Analista Programadora – MCTS SQL
Server
Introducción
Los procedimientos almacenados
permiten ejecutar procedimientos parecidos a los usados en un
lenguaje de programación, pero directamente desde la base de
datos, optimizando el rendimiento y la velocidad del mismo. De
hecho, a la hora de hacer consultas y operaciones a una base
de datos, es recomendable usar siempre procedimientos
almacenados, en la medida de lo posible.
¿Cómo creo un procedimiento almacenado?
Para crear un procedimiento almacenado sobre una BBDD,
el la carpeta Programación, pulsamos botón derecho y elegimos
“Nuevo procedimiento almacenado”.
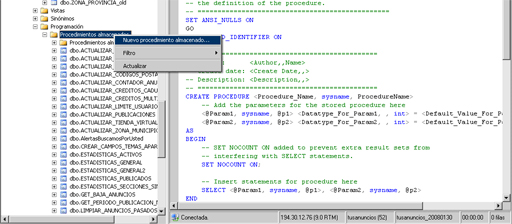
Aparecerá un plantilla formada
por un CREATE PROCEDURE seguido de las variables de entrada o
salida, un BEGIN a partir del cual escribiríamos el código
correspondiente para ese procedimiento y un END GO para dar
por finalizado el mismo.
La sentencia CREATE PROCEDURE
que aparece en la plantilla del nuevo procedimiento, hará que
cuando terminemos de escribirlo y después de analizarlo (el
icono de la parte superior con un visto), cuando pulsemos
“Analizar” (icono en forma de admiración de la barra de
herramientas), el nuevo procedimiento se cree.
Cuando pulsemos el botón
“Ejecutar” (icono con forma de signo de admiración) NO se
ejecuta el procedimiento en sí, sino la sentencia CREATE
PROCEDURE que creará el procedimiento en la base de datos.
Esta sentencia sólo se ejecutará una vez. A partir de
entonces, si queremos hacer algún cambio en el procedimiento,
usaremos la sentencia ALTER en lugar de CREATE para que éstos
se guarden.
Para ejecutar el procedimiento
almacenado en sí, existen dos formas. Hacer una ejecución
parcial, o una total. Para realizar una ejecución parcial,
seleccionamos la parte del procedimiento y pulsamos
“Ejecutar”. Para hacer una ejecución total, pulsamos
botón derecho sobre el procedimiento en el treeview y
seleccionamos la opción de ejecutar procedimiento
almacenado.
Si el procedimiento se ha
ejecutado correctamente, devolverá un 0. En caso contrario,
mostrará un mensaje con la línea de código errónea que ha
producido que no se haya completado el procedimiento.
Nombre del
procedimiento
Para asignar un nombre a un procedimiento,
escribimos la siguiente sentencia:
|
ALTER
PROCEDURE [dbo].[NOMBRE_DEL_PROCEDIMIENTO]
|
Paso de
variables de un procedimiento
Las variables necesarias para
el procedimiento, se declaran justo después del nombre del
mismo, antes del BEGIN con el tipo correspondiente a
continuación:
|
ALTER PROCEDURE [dbo].[NOMBRE_DEL_PROCEDIMIENTO]
@ID_USUARIO bigint,
@ID_TIPO_PERFIL int,
@ID_CORREO = 0,
@ID_PASSWORD output
AS
BEGIN
…
|
La tercera variable, significa
que puede venir o no. La cuarta variable es de salida. Le
pasamos una variable y podemos recuperar su valor en el
programa.
Declaración de variables
Las variables que se vayan a
usar en el procedimiento se declaran dentro del BEGIN
principal del procedimiento
|
ALTER PROCEDURE [dbo].[NOMBRE_DEL_PROCEDIMIENTO]
AS
BEGIN
DECLARE @ID_ZONA_NEW AS BIGINT
DECLARE
@DESC_ZONA_NEW AS VARCHAR(1000)
DECLARE
@EXISTE_ZONA AS BIT
DECLARE @DATEVAR
AS DATETIME
|
El tipo de las variables
coincide con los tipos de SQL Server. Deben ser iguales los
elementos de la tabla con la variable declarada.
Para inicializar las
variables, usamos la sentencia SET.
|
SET @ID_ZONA_NEW = null
SET @DATEVAR = getdate()
|
También se puede usar la sentencia
SELECT.
|
SELECT @NOMBRE_VARIABLE =‘PRUEBAS’
|
La diferencia entre ellas es
que la sentencia SELECT mostrará un mensaje en el cuadro de
diálogo inferior al ejecutar el procedimiento
Sentencias
de programación
La sentencia IF es igual a la
de programación. Cada parte se engloba en un BEGIN y en un
END, de la siguiente forma:
|
IF @ID_TIPO_PERFIL = 1
BEGIN
...
END
ELSE
BEGIN
...
END
|
-- ELSEIF
|
IF @ID_TIPO_PERFIL = 1
BEGIN
...
END
ELSE
BEGIN
IF @CODIGO_POSTAL_TA ISNULL
BEGIN
...
END
END
|
La sentencia de programación WHILE se usa de
la siguiente forma:
|
WHILE @VARIABLE > 0
BEGIN
...
BREAK
CONTINUE
END
|
Se puede usar BREAK para salir
forzosamente del bucle, o CONTINUE para continuar.
Otras funciones son WAITFOR,
que espera un cierto tiempo a seguir con la ejecución del SP y
RETURN, que sale del SP sin ejecutar nada más.
Funciones
Algunas funciones que incluye T-Sql que
pueden ser de utilidad son las siguientes:
ASCII
Devuelve el cógido ASCII del carácter más a
la izquierda de una expreion de caracteres.
CHAR
Una función de cadena que convierte un
código ASCII int en un carácter.
LEN
Devuelve el número de caracteres.
LTRIM
Devuelve una expresión de caracteres después
de quitar los espacios en blanco de la izquierda.
REPLACE
Reemplaza por una tercera expresión todas
las apariciones de la segunda expresión.
SUBSTRING
Devuelve parte de una expresion de
caracteres.
UPPER
Devuelve una expresión en mayúscula.
GETDATE
Devuelve la fecha y la hora actuales del
sistema.
DATEADD
Devuelve un valor DateTime nuevo que se basa
en la suma de un intervalo a la fecha especificada.
DATEDIFF
Devuelve el número de límites de fecha y
hora que hay entre dos fechas especificadas.
DATEPART
Devuelve un entero que representa la parte
de la fecha especificada de la fecha indicada.
Variables
del sistema de utilidad
@@IDENTITY y
SCOPE_IDENTITY()
Cuando insertamos un nuevo
valor en una tabla, podemos obtener el identificador de ese
nuevo registro. Si tenemos una columna, con identidad (lo que
sería equivalente a un autonumérico), es decir, que es la bbdd
quien le asigna el valor, con @@IDENTITY recuperamos ese
valor.
Ejemplo:
|
DECLARE
@NUEVO_ID AS BIGINT
INSERT INTO
NOMBRE_TABLA
(CAMPO1, CAMPO2)
VALUES
(VALOR1, VALOR2)
SELECT @NUEVO_ID =@@IDENTITY
INSERT INTO
NOMBRE_TABLA
(CAMPO1, CAMPO2)
VALUES
(VALOR1, VALOR2)
SELECT @NUEVO_ID =SCOPE_IDENTITY()
|
En un procedimiento almacenado
sin “Triggers” de los que hablaremos a continuación, ambas
sentencias nos devuelven lo mismo. Pero, si por ejemplo,
nuestro INSERT activa otro procedimiento que a su vez, esta
llamando a otro INSERT, el valor que recibirá el @@IDENTITY
será el del segundo insert, que no nos interesa. Por eso, es
recomendable usar SCOPE_IDENTITY().
@@ERROR
Cuando realizamos cualquier
operación, si no se produce ningún error, esta variable se
mantiene a 0, sino, obtendrá otro valor.
Es útil crear una variable de
tipo entero a la que le asignamos este valor cada vez que
realizamos una operación, para verificar que si ésta se ha
realizado correctamente.
Transacciones
Se declaran con BEGIN TRAN. A
partir de esta sentencia, todo las operaciones que realicemos
se van guardando internamente. Si al final del procedimiento
ejecutamos COMMIT TRAN, todas las operaciones escritas a
partir del BEGIN TRAN se ejecutaran. Si ponemos ROLLBACK TRAN,
de desharán todas las acciones escritas a partir del BEGIN
TRAN. Esto es muy útil para evitar que si un
procedimiento se queda a medias o se ha producido algún error,
datos inútiles se queden insertados o actualizados.
Ejemplo:
|
DECLARE
@ERROR AS INT
SELECT @ERROR = @error +abs(@@error)
BEGIN TRAN
TRANSACCION_PRUEBA
....
SELECT @ERROR = @error +abs(@@error)
IF @ERROR <> 0
BEGIN
ROLLBACK
TRAN
TRANSACCION_PRUEBA
END
ELSE
BEGIN
COMMIT TRAN
TRANSACCION_PRUEBA
END
|
Nota: TRY
y CATCH
Además del @@ERROR existe una
sentencia más cómoda a la hora de detectar que se ha producido
un error en nuestro procedimiento y ejecutar un ROLLBACK en
consecuencia. Al igual que en C# se puede abrimos un try para
la secuencias de comandos que podrían dar error y un catch
para realizar un “deshacer” si esto ocurre.
|
BEGIN TRAN (el nombre solo es
necesario en el caso de que haya varias
transacciones)
BEGIN TRY
....
COMMIT TRAN
END TRY
BEGIN CATCH
ROLLBACK
TRAN
END CATCH
|
Cursores
Un cursor nos permite movernos
por los registros de una consulta (el resultado obtenido de
una select) uno por uno. Esto es muy útil si lo que queremos
es realizar una accion si el id de un registro es autonumerico
y no lo conocemos hasta que se inserta el registro y queremos
insertar ese id en cualquier otra tabla.
Lo primero que tenemos que
hacer es declarar el cursor con la sentencia que nos devolverá
los datos
DECLARE NombreCursor CURSOR FOR
(la sentencia SQL que nos devolverá los datos)
A continuación abrimos el
cursor
OPEN NombreCursor
Para leer los registros del
cursor, usamos la sentencia
FETCH NEXT FROM NombreCursor INTO
(la variable o variables en la que
guardaremos el contenido de los resultados de la
select)
Una vez tenemos el
contenido guardado, podemos usar esas variables para las
acciones que necesitemos. Iremos recorriendo con el cursor
cada una de las filas que nos ha devuelto la consulta mientras
el estado sea correcto (@@fetch_status=
0) y leyendo el siguiente registro al final del
mismo.
No debemos olvidar cerrar y
liberar el espacio creado por el cursor al final, con las
sentencias CLOSE y DEALLOCATE respectivamente.
Ejemplo:
|
DECLARE
@ID_CODIGO_POSTAL AS BIGINT
DECLARE
@DESC_CODIGO_POSTAL AS VARCHAR
DECLARE
@ZONA AS BIGINT
--DECLARAMOS EL CURSOR
DECLARE
cursorCodigoPostal CURSORFOR
SELECT
ID_CODIGO_POSTAL,
DESC_CODIGO_POSTAL,
FROM CODIGOS_POSTALES
--ABRIMOS EL CURSOR
OPEN cursorCodigoPostal
--LEEMOS EL PRIMER REGISTRO
FETCH NEXT FROM
cursorCodigoPostal
INTO
@ID_CODIGO_POSTAL,
@DESC_CODIGO_POSTAL
--MIENTRAS EL STATUS SEA 0
WHILE @@fetch_status = 0
BEGIN
--REALIZAMOS LAS ACCIONES QUE
QUERAMOS
SELECT @ID_ZONA = ID_ZONA
FROM ZONA_CP
WHERE ID_CODIGO_POSTAL = @ID_CODIGO_POSTAL
UPDATE ANUNCIOS
SET ID_ZONA = @ID_ZONA,
SET
DESC_CODIGO_POSTAL
=
@DESC_CODIGO_POSTAL
WHERE ID_CODIGO_POSTAL = @ID_CODIGO_POSTAL
FETCH NEXT FROM
cursorCodigoPostal
INTO
@ID_CODIGO_POSTAL,
@DESC_CODIGO_POSTAL
END
CLOSE cursorCodgioPostal
DEALLOCATE
cursorCodgioPostal
END
|
Nota:
Tablas Temporales
Los cursores tienen una
desventaja. Mientras el cursor permanece abierto, las tablas a
las que afecte se mantienen bloqueadas mientras éste este en
funcionamiento. No tiene sentido que se permita insertar o
modificar un registro en ese momento, porque los resultados
obtenidos podrían ser distintos a los que hubiera luego en la
tabla. Pero tampoco tiene sentido que la tabla se quede
bloqueada, por lo que es, en muchas ocasiones recomendable,
usar una tabla temporal intermedia en la que guardaremos los
resultados de la consulta y sobre la cual abriremos el cursor.
La tabla temporal desaparecerá el final del
procedimiento.
|
-- DECLARACION DE
VARIABLES
DECLARE
@ID_CODIGO_POSTAL AS BIGINT
DECLARE
@DESC_CODIGO_POSTAL AS VARCHAR
DECLARE
@ZONA AS BIGINT
-- TABLA TEMPORAL PARA
CONSULTA
DECLARE
@TMP_CODIGOS_POSTALES
Table
(
ID_CODIGO_POSTAL
BIGINT,
DESC_CODIGO_POSTAL VARCHAR
)
-- Insertamos en la tabla temporal
INSERT @TMP_CODIGOS_POSTALES
(
ID_CODIGO_POSTAL,
DESC_CODIGO_POSTAL
)
SELECT
ID_CODIGO_POSTAL,
DESC_CODIGO_POSTAL
FROM
CODIGOS_POSTALES
-- Declaramos el
cursor de la tabla temporal
DECLARE
CursorTablaTemp CURSORFOR
SELECT
ID_CODIGO_POSTAL ,
DESC_CODIGO_POSTAL
FROM @TMP_CODIGOS_POSTALES
-- Abrimos cursor
OPEN CursorTablaTemp
-- Leemos el primer registro del
cursor
FETCH NEXT FROM CursorTablaTemp
INTO
@ID_CODIGO_POSTAL ,
@DESC_CODIGO_POSTAL
WHILE @@FETCH_STATUS = 0
BEGIN
SELECT @ID_ZONA =
ID_ZONA
FROM ZONA_CP
WHERE ID_CODIGO_POSTAL = @ID_CODIGO_POSTAL
UPDATE ANUNCIOS
SET ID_ZONA = @ID_ZONA,
SET
DESC_CODIGO_POSTAL
=
@DESC_CODIGO_POSTAL
WHERE ID_CODIGO_POSTAL = @ID_CODIGO_POSTAL
FETCH NEXT FROM CursorTablaTemp
INTO
@ID_CODIGO_POSTAL ,
@DESC_CODIGO_POSTAL
END
CLOSE CursorTablaTemp
DEALLOCATE
CursorTablaTemp
END
|
| 


